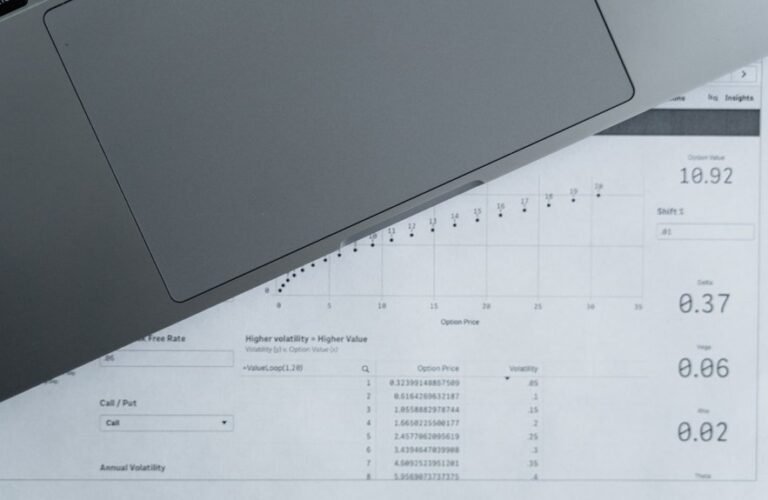
Web entity classification and noise detection files serve as artifacts for tracing provenance and evaluating data reliability across multilingual content. They emphasize standardized labeling, versioning signals, timestamps, and confidence markers to support auditable workflows. The discussed file raises questions about signal versus noise, preprocessing rigor, and reproducible criteria. Its structured approach invites scrutiny of normalization, multilingual handling, and drift resistance, leaving unresolved how such provenance mechanisms scale in real-world pipelines and what tradeoffs they entail for accuracy and transparency.
What Is Web Entity Classification & Noise Detection and Why It Matters
Web entity classification and noise detection concern the systematic assignment of online items to predefined categories while identifying and filtering irrelevant or misleading data.
The analysis emphasizes objective criteria, reproducibility, and transparent methodology.
In practice, noise detection safeguards data reliability, enabling provenance labeling and traceable origins.
The approach supports freedom by revealing structure, reducing bias, and fostering trust through rigorous, empirical evaluation of classification decisions.
How the Mystery File Naming Reveals Provenance, Labels, and Data Reliability
The naming convention of mystery files serves as a concrete axis for tracing provenance, assigning labels, and evaluating data reliability. Systematic patterns encode source lineage, versioning, and curator intent, enabling provenance labeling and auditability. Distinct tokens signal verification steps, timestamps, and confidence levels, supporting cross-domain comparisons. This disciplined encoding underpins trust, reuse, and critical appraisal of data, fostering transparency without compromising analytical independence.
Assessing Classification Quality: Signals, Noise, and Robust Preprocessing Techniques
Assessing classification quality requires a disciplined separation of signal from noise and the application of robust preprocessing strategies. The evaluation hinges on empirical benchmarks, error diagnostics, and reproducible workflows. Signals are scrutinized against noise detection metrics, with results anchored in transparent data provenance. Effective preprocessing reduces spurious associations, improves generalization, and clarifies classifier behavior under diverse, real-world conditions.
Building Resilient Pipelines: Cleaning, Normalization, and Multilingual Considerations
Building resilient data pipelines requires deliberate cleaning, consistent normalization, and careful handling of multilingual content to maintain stability across diverse inputs. The approach emphasizes traceable data provenance and labeling reliability as core evaluative metrics, enabling auditability and error containment. Empirical comparisons reveal that standardized pipelines reduce drift, while multilingual normalization mitigates misclassification risks, supporting scalable, freedom-friendly data-driven decision making.
Frequently Asked Questions
How Is Bias Measured in Web Entity Classification Outcomes?
Bias measurement in web entity classification outcomes is quantified via metrics like accuracy, precision, recall, F1, and calibration, complemented by fairness gaps across groups; real time labeling enables ongoing monitoring, revealing drift and opportunistic bias in streaming results.
What About Real-Time Updates to Labeled Datasets?
Real-time labeling adapts labels as data shifts, mitigating dataset drift; however, it risks instability without robust governance, requiring continuous monitoring, versioning, and validation to preserve reproducibility, integrity, and auditable performance across evolving labeled datasets.
Can You Compare Noise Detection Across Languages?
Anachronism: quantum annotations aside, the comparison shows language equivalence varies with linguistic features, and cross lingual noise differs by script, morphology, and training data; empirical metrics reveal higher noise in low-resource pairs than high-resource pairs.
How Scalable Are Preprocessing Techniques Across Corpora?
Scaling noise handling varies by corpus; preprocessing can be broadly scalable but cross language preprocessing often incurs diminishing returns due to linguistic diversity, data quality, and annotation standards, demanding empirical benchmarking and modular pipelines for robust performance.
What Safeguards Prevent Data Leakage in Pipelines?
Safeguards include pipeline isolation and access controls; data anonymization and redact identifiers reduce leakage risk, while data provenance and model auditing enable traceability. Security testing, leak containment, and rigorous governance ensure ongoing compliance and auditable accountability.
Conclusion
In the archive’s quiet chambers, signals and shadows steel themselves into a disciplined duet. The provenance labels act as lighthouses, guiding judgments through foggy multilingual tides. Noise, once unruly, is tamed by normalization, auditable steps, and repeatable criteria—each a counterweight to drift. The file thus crystallizes into a reliable instrument: a compass whose needle, toward clarity, never rests, revealing truth through structured scrutiny and verifiable lineage. In this symbol, method becomes meaning.