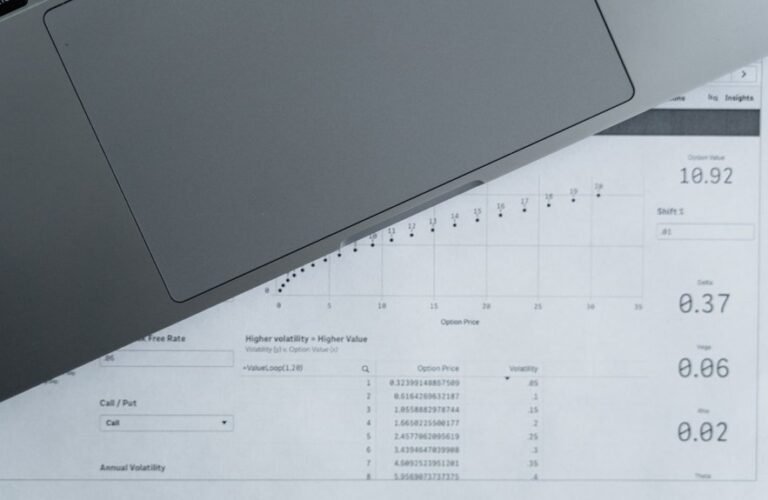
Network and Keyword Validation establishes constraints that reduce misconfigurations by aligning inputs to canonical terms and predefined patterns. By creating unique keys and stable semantic mappings, it supports traceable provenance across diverse datasets. Parsing mixed identifiers reveals common pitfalls and robust techniques for normalization. Scaling these practices demands automation, systematic testing, and maintainable pipelines to ensure reproducible decisions. The implications span cross-domain reliability, yet practical implementation details invite further examination for those tasked with enforcing consistency across complex datasets.
How Network and Keyword Validation Prevent Misconfigurations
Network and keyword validation serves as a proactive safeguard against misconfigurations by ensuring that inputs align with predefined constraints before they influence system behavior.
The analysis demonstrates that network validation constrains data flows, while keyword mapping aligns labels with canonical terms.
This disciplined approach reduces misconfiguration prevention risks, supports predictable operations, and provides traceable evidence for configuration decisions and forensic review.
Building Unique Keys and Semantic Mappings for Reliable Data
Building unique keys and semantic mappings for reliable data follows from the prior focus on preventing misconfigurations by validating inputs. Precision guides the process: establish stable validation mapping rules, ensure consistency across datasets, and document semantic keys to enable reproducible interpretation. This approach reduces ambiguity, supports scalable integration, and preserves data provenance while permitting flexible, freedom-conscious analysis and trustworthy downstream decisions.
Parsing Mixed Identifiers: Techniques and Common Pitfalls
Parsing mixed identifiers presents a set of practical challenges that arise when alphanumeric strings encode multiple semantic layers. The section surveys parsing techniques that separate tokens, normalize formats, and preserve provenance. It highlights common pitfalls, such as ambiguous delimiters and inconsistent casing, and recommends reproducible pipelines. Key takeaways include robust parsing identifiers and precise Semantic mappings to ensure reliable cross-domain validation.
Scaling Validation: Automation, Testing, and Maintainability
Automation, testing, and maintainability are central to scaling validation, ensuring that validation processes remain reliable as scope and complexity grow.
The discussion emphasizes repeatable, automated pipelines, rigorous test coverage, and modular tooling to reduce brittleness.
Evidence-based practices justify investments in scalable architectures, monitoring, and documentation.
This approach supports scaling validation and automation testing while preserving clarity, adaptability, and freedom for ongoing improvements.
Frequently Asked Questions
How Do Network Validations Handle Evolving Data Schemas?
Network validators address evolving data schemas through schema evolution governance, implementing versioning strategies and monitoring data schema changes to ensure compatibility. They enforce backward- and forward-compatibility, track lineage, and provide safe migrations while preserving data integrity and traceability.
What Security Risks Arise From Weak Keyword Mappings?
Weak mapping increases attack surface by enabling inference and injection; inconsistent schema amplifies risk through schema drift, divergent validations, and data leakage. A disciplined approach—strict mappings, versioned schemas, and continuous validation—reduces exposure and preserves integrity.
Can Mixed Identifiers Affect Data Lineage Tracing?
Mixed identifiers can complicate data lineage tracing by obscuring source-to-target mappings, yet when integrated with evolving data and robust network schemas, they preserve traceability. The evidence supports careful governance, ensuring transparency despite identifier variation.
How Is User Feedback Incorporated Into Validation Rules?
User feedback informs validation incorporation by guiding rule adjustments, triggering schema evolution, and refining keyword mapping; it strengthens data lineage awareness while addressing security risks and cost considerations with evidence-based, methodical changes.
What Are Cost Considerations for Large-Scale Validation Pipelines?
Cost considerations for large-scale validation pipelines include compute, storage, and data governance compliance; scalable architectures require automation and monitoring. Schema evolution and modular validation reduce waste, while cost-aware data governance policies guide retention, provenance, and quality assurance across expansive datasets.
Conclusion
Network and keyword validation establishes deterministic keys and stable semantic mappings, ensuring traceable provenance across mixed identifiers. By enforcing constraints and automating tests, misconfigurations are prevented and reproducibility is enhanced. Some may doubt brevity suffices; however, concise validation yields clear audit trails and faster remediation. The method remains rigorous: parse inputs, constrain data flows, and maintain canonical term mappings. Together, these practices deliver reliable, scalable, and auditable configurations for diverse datasets.